Qu'est-ce qu'un Transformer ?
Découvrez l'architecture qui a révolutionné l'Intelligence Artificielle en 2017 et qui alimente aujourd'hui ChatGPT, GPT-4, Claude, Gemini et tous les grands modèles de langage.
Une analogie simple pour commencer
🧠 Avant les Transformers : les RNN
Imaginez que vous lisez un livre en ne regardant qu'un seul mot à la fois, dans l'ordre, sans jamais pouvoir revenir en arrière ou sauter des pages. Vous devez vous souvenir de tout ce que vous avez lu précédemment dans votre mémoire limitée.
C'est ainsi que fonctionnaient les RNN (Réseaux de Neurones Récurrents) : ils lisaient le texte mot par mot, séquentiellement, et avaient du mal à se souvenir des informations lointaines.
Problème : Lent (séquentiel), perte de mémoire sur les longues phrases, difficulté à capturer les relations à longue distance.
⚡ Avec les Transformers
Maintenant, imaginez que vous pouvez voir tous les mots de la page en même temps, et que votre cerveau peut instantanément identifier les relations entre n'importe quels mots, même s'ils sont très éloignés.
C'est exactement ce que font les Transformers : ils traitent tous les mots simultanément et utilisent le mécanisme d'attention pour comprendre les relations entre eux, quelle que soit leur distance.
Avantages : Rapide (parallèle), mémoire parfaite, capture toutes les relations contextuelles, scalable à des milliards de paramètres.
Comparaison visuelle
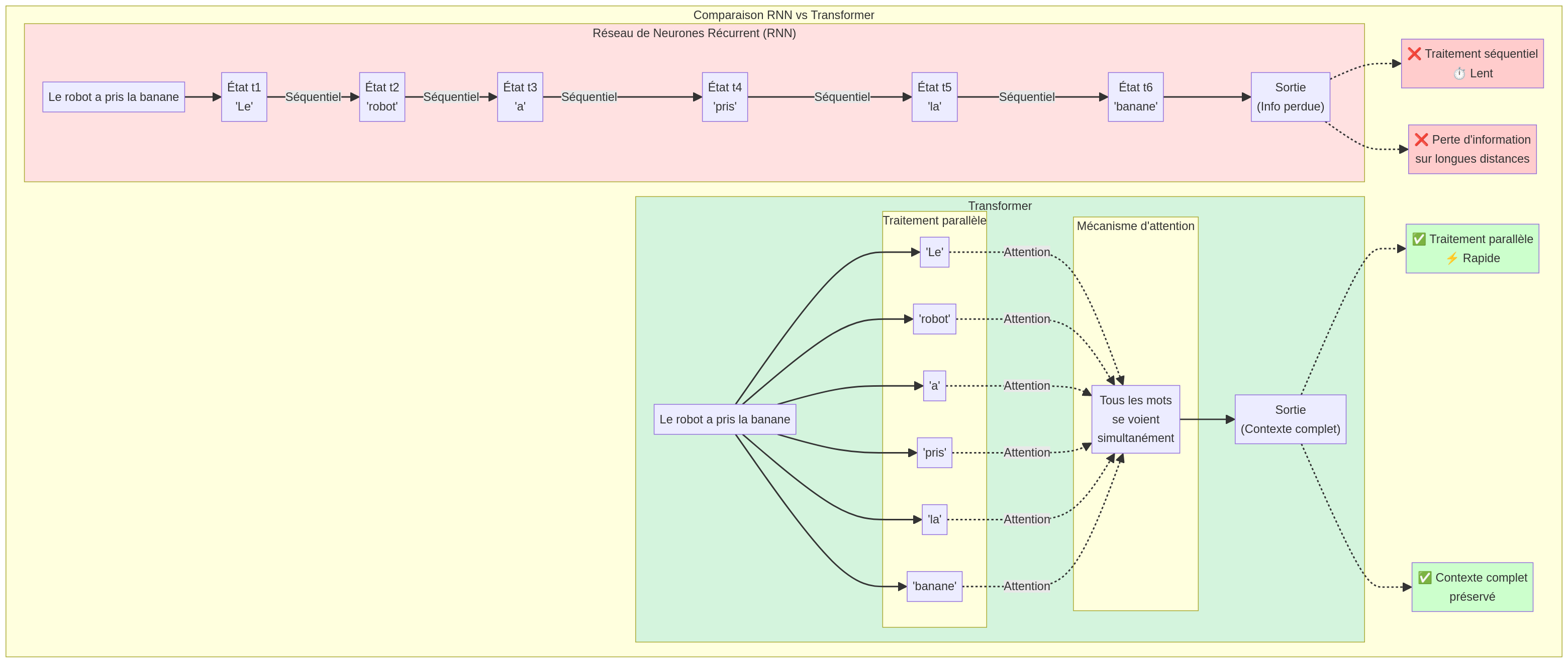
À gauche : RNN traite séquentiellement. À droite : Transformer traite en parallèle avec attention globale.
Phrase à traiter :
Le chat mange la souris
Séquentiel : Chaque mot doit attendre que le précédent soit traité. Comme lire un livre mot par mot, impossible de sauter ou de lire en parallèle.
Parallèle : Tous les mots sont traités en même temps grâce au mécanisme d'attention. Comme voir toute la phrase d'un coup d'œil !
💡 Pourquoi c'est révolutionnaire ?
RNN : Doit traiter les mots un par un, dans l'ordre. Pour une phrase de 100 mots, il faut 100 étapes séquentielles. Impossible à paralléliser sur GPU.
Transformer : Traite tous les mots simultanément grâce au mécanisme d'attention. Pour 100 mots, une seule étape suffit ! C'est ce qui permet d'entraîner des modèles avec des milliards de paramètres.
Sur une phrase de 1000 mots, le Transformer est théoriquement 1000x plus rapide !
"Attention is All You Need" (2017)
En juin 2017, des chercheurs de Google Brain (Vaswani et al.) publient un paper révolutionnaire qui va changer l'histoire de l'IA. Leur message : on n'a plus besoin de récurrence ni de convolution, l'attention suffit.
Self-Attention
Chaque mot peut "regarder" tous les autres mots simultanément et décider lesquels sont importants pour le comprendre.
Parallélisation
Tous les mots sont traités en même temps, permettant un entraînement beaucoup plus rapide sur GPU/TPU.
Multi-Head Attention
Plusieurs mécanismes d'attention en parallèle capturent différents types de relations (syntaxe, sémantique, etc.).
Les auteurs principaux
Le paper "Attention is All You Need" a été écrit par une équipe de 8 chercheurs de Google Brain et Google Research :
Architecture complète d'un Transformer

Architecture originale du Transformer avec encodeur (gauche) et décodeur (droite)
L'encodeur transforme la séquence d'entrée (par exemple, une phrase en français) en une représentation riche et contextuelle. Il est composé de N couches identiques(généralement 6 ou 12), chacune contenant :
Multi-Head Self-Attention
Permet à chaque mot de "regarder" tous les autres mots de la phrase pour comprendre le contexte global.
Feed-Forward Network
Un réseau de neurones dense appliqué indépendamment à chaque position pour transformer les représentations.
Connexions résiduelles & Layer Normalization
Facilitent l'entraînement de réseaux profonds en évitant la disparition du gradient.
Le décodeur génère la séquence de sortie (par exemple, la traduction en anglais) un mot à la fois, en utilisant à la fois la sortie de l'encodeur et les mots déjà générés. Il contient également N couches identiques, chacune avec :
Masked Multi-Head Self-Attention
Similaire à l'encodeur, mais avec un masque qui empêche de "regarder" les mots futurs (pour la génération auto-régressive).
Cross-Attention (Encoder-Decoder Attention)
Permet au décodeur de "regarder" la sortie de l'encodeur pour utiliser l'information de la phrase source.
Feed-Forward Network
Identique à celui de l'encodeur.
Les composants essentiels
Contrairement aux RNN qui traitent les mots dans l'ordre, les Transformers voient tous les mots simultanément. Pour qu'ils comprennent l'ordre des mots, on ajoute un encodage positionnel à chaque mot.
C'est comme numéroter les pages d'un livre : même si vous les mélangez, les numéros vous permettent de retrouver l'ordre original.
Chaque mot est d'abord converti en un vecteur de nombres(typiquement 512 ou 768 dimensions) qui capture son sens sémantique.
Des mots similaires (comme "chat" et "chaton") auront des vecteurs proches dans l'espace vectoriel.
Normalise les activations de chaque couche pour maintenir des valeurs stables et faciliter l'entraînement de réseaux très profonds.
C'est comme ajuster le volume de chaque instrument dans un orchestre pour qu'aucun ne domine les autres.
Des "raccourcis" qui permettent à l'information de passer directement d'une couche à une autre, évitant le problème de la disparition du gradient.
Formule : Output = LayerNorm(Input + Sublayer(Input))
Visualiseur interactif : Positional Encoding
Explorez comment les positions sont encodées avec des fonctions sinusoïdales. Ajustez les paramètres pour comprendre visuellement la formule mathématique.
La phrase complète est découpée en mots (tokens). Chaque mot reçoit un numéro de position.
💡 Pourquoi cette transformation ?
Les Transformers ont besoin de deux informations : le sens du mot (embedding) et sa position dans la phrase (positional encoding). En additionnant ces deux vecteurs, on obtient une représentation riche qui permet au modèle de comprendre à la fois le contexte sémantique et l'ordre des mots. Par exemple, "Le chat mange la souris" a un sens différent de "La souris mange le chat" !
Position du token dans la séquence (mise en surbrillance dans la heatmap)
Taille du vecteur d'embedding
Nombre de positions à visualiser
Comparez deux positions côte à côte
Formule du Positional Encoding :
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
Les dimensions paires utilisent sin, les impaires utilisent cos. Les fréquences diminuent exponentiellement avec la dimension.
Valeurs de PE pour la position 10 à travers toutes les dimensions
• Les courbes bleues (sin) et violettes (cos) oscillent entre -1 et 1
• Les dimensions basses (à gauche) oscillent rapidement, les hautes (à droite) lentement
• Cette variation de fréquence permet au modèle de distinguer les positions proches et lointaines
💡 Pourquoi sin/cos ?
Les fonctions sinusoïdales permettent au modèle d'apprendre facilement les positions relatives : PE(pos+k) peut être exprimé comme une combinaison linéaire de PE(pos), facilitant la généralisation à des séquences plus longues.
🎯 Fréquences multiples
Chaque dimension encode la position à une fréquence différente. Les basses fréquences capturent les positions globales (début/milieu/fin), les hautes fréquences distinguent les positions adjacentes.
Les variantes modernes
Depuis 2017, de nombreuses variantes du Transformer original ont été développées pour différents cas d'usage. Voici les plus importantes :
Utilise uniquement l'encodeur. Excellent pour comprendre le texte (classification, question-réponse, analyse de sentiment).
Exemples : BERT, RoBERTa, ALBERT, DistilBERT
Utilise uniquement le décodeur. Excellent pour générer du texte (rédaction, code, conversation).
Exemples : GPT-2, GPT-3, GPT-4, LLaMA, Mistral, Claude
Utilise encodeur + décodeur. Idéal pour les tâches de transformation (traduction, résumé, paraphrase).
Exemples : T5, BART, mT5, mBART
Pourquoi les Transformers sont révolutionnaires ?
Entraînement 10-100x plus rapide que les RNN grâce au traitement parallèle sur GPU/TPU
Peut être agrandi à des milliards de paramètres (GPT-4 : ~1.76 trillion)
Capture les relations à longue distance sans perte d'information
Fonctionne pour le texte, les images, l'audio, la vidéo, le code, etc.
Quelle est la principale innovation introduite par les Transformers ?
Quiz Vrai ou Faux
Validez votre compréhension des concepts clés avec ce format simple et pédagogique
Les Transformers ont été inventés par Google en 2017.
Votre retour est précieux pour améliorer cette page. Partagez votre expérience ci-dessous.
Comment évaluez-vous cette page ?
Pages connexes
Continuez votre apprentissage avec ces sujets liés