Le Mécanisme d'Attention
Découvrez le secret qui permet aux Transformers de comprendre le contexte et les relations entre les mots, révolutionnant ainsi le traitement du langage naturel.
Qu'est-ce que l'attention ?
L'attention est un mécanisme qui permet au modèle de se concentrer sur les parties les plus pertinentes d'une séquence lors du traitement de chaque élément. C'est comme lorsque vous lisez une phrase : votre cerveau ne traite pas tous les mots de manière égale, mais se concentre sur ceux qui sont importants pour comprendre le sens.
Dans les Transformers, chaque mot peut "regarder" tous les autres mots de la phrase et décider lesquels sont importants pour le comprendre. Ce processus s'appelle Self-Attention (auto-attention).
Par exemple, dans la phrase "Le robot a pris la banane car il avait faim", le mot "il" doit comprendre qu'il fait référence à "robot" et non à "banane". L'attention permet au modèle de créer ce lien automatiquement.
Vision globale
Chaque mot "voit" tous les autres mots simultanément
Connexions pondérées
Des scores d'attention déterminent l'importance de chaque relation
Apprentissage automatique
Le modèle apprend quelles relations sont importantes
Comment fonctionne la Self-Attention ?
Pour chaque mot de la phrase, le modèle crée trois représentations vectorielles :
Query (Q)
"Qu'est-ce que je cherche ?" - La requête que le mot pose aux autres mots
Key (K)
"Voici ce que je suis" - L'identité du mot pour être trouvé par les autres
Value (V)
"Voici l'information que je contiens" - Le contenu sémantique du mot
Ces trois vecteurs sont obtenus en multipliant l'embedding du mot par trois matrices de poids différentes (WQ, WK, WV), apprises pendant l'entraînement.
Pour chaque paire de mots, on calcule un score d'attention en faisant le produit scalaire entre la Query du premier mot et la Key du second mot :
Le score est divisé par √d_k (racine carrée de la dimension des vecteurs) pour stabiliser les gradients pendant l'entraînement. Un score élevé signifie que les deux mots sont fortement liés.
Les scores bruts sont passés dans une fonction Softmax qui les transforme en probabilités (valeurs entre 0 et 1 dont la somme vaut 1) :
Cela permet d'interpréter les scores comme des "poids d'attention" : quelle proportion d'attention chaque mot doit recevoir.
Enfin, on calcule une somme pondérée des Values de tous les mots, en utilisant les poids d'attention comme coefficients :
Le résultat est une nouvelle représentation du mot qui intègre les informations contextuelles des autres mots, pondérées par leur pertinence.
Schémas explicatifs
Schéma du mécanisme Self-Attention
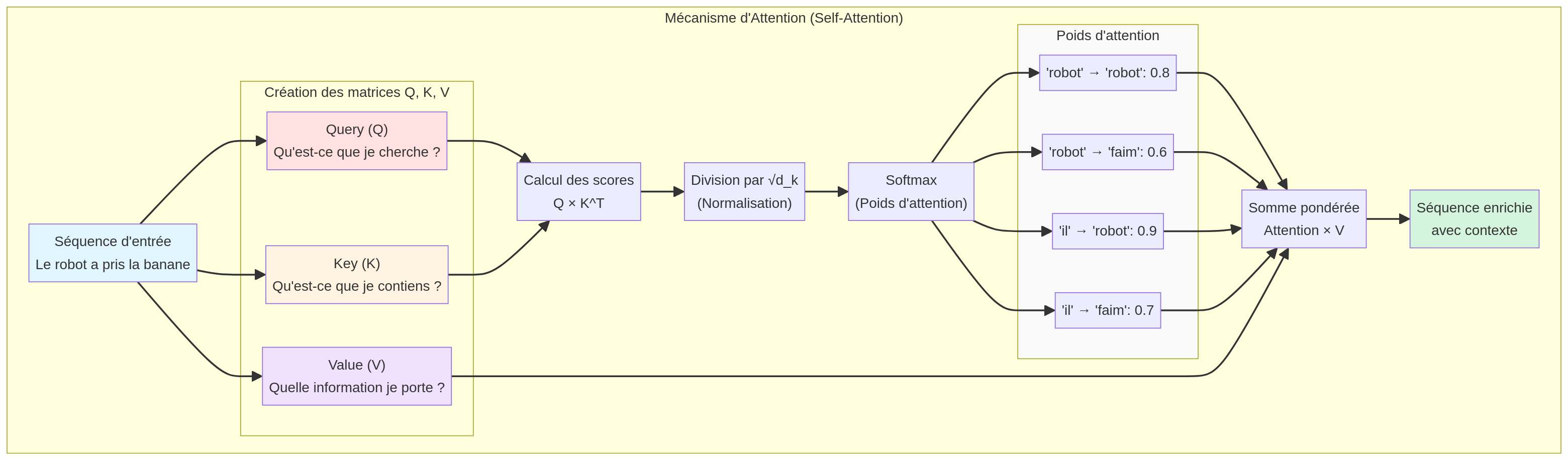
Schéma du Multi-Head Attention
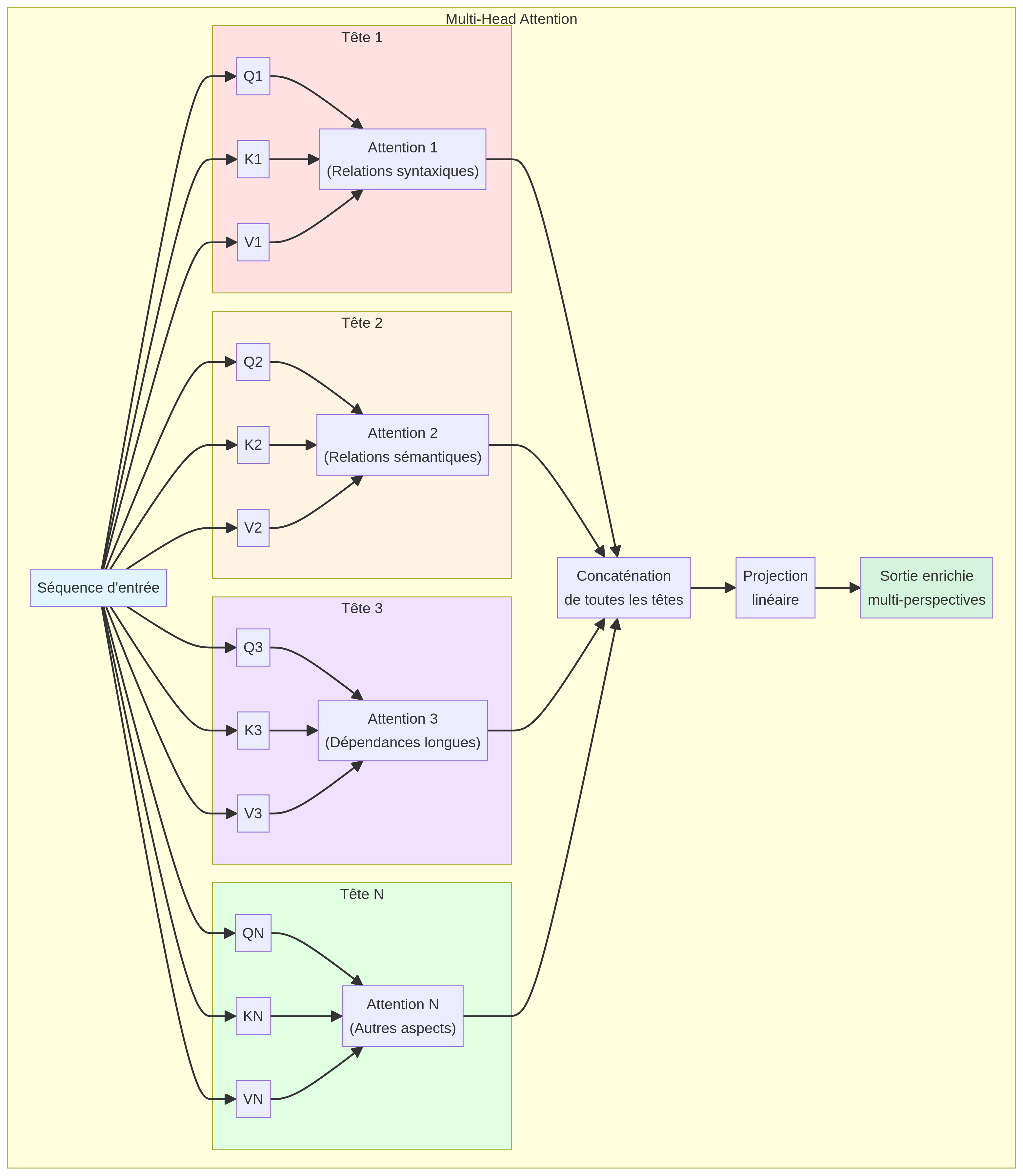
Le Multi-Head Attention applique plusieurs mécanismes d'attention en parallèle, permettant au modèle de capturer différents types de relations simultanément.
Multi-Head Attention
Au lieu d'utiliser un seul mécanisme d'attention, les Transformers en utilisent plusieurs en parallèle (typiquement 8 ou 16 "têtes"). Chaque tête apprend à détecter des patterns différents.
Diversité des relations : Une tête peut se concentrer sur les relations syntaxiques (sujet-verbe), une autre sur les relations sémantiques (synonymes), etc.
Robustesse : Si une tête fait une erreur, les autres peuvent compenser.
Expressivité : Le modèle peut capturer des patterns complexes et nuancés que ne pourrait pas détecter une seule tête.
1. Division : Les vecteurs Q, K, V sont divisés en h parties (h = nombre de têtes).
2. Attention parallèle : Chaque tête calcule son propre mécanisme d'attention indépendamment.
3. Concaténation : Les sorties de toutes les têtes sont concaténées et projetées pour former le résultat final.
Phrase analysée :
Le chat noir mange la souris grise
Sélectionnez les têtes d'attention à visualiser :
Têtes actives :
Capture les relations sujet-verbe et la structure grammaticale
Identifie les mots liés par le sens (synonymes, contexte)
Relie les pronoms à leurs référents (il → chat)
Connecte des mots éloignés dans la phrase
💡 En termes simples :
Au lieu d'avoir une seule "vue" de la phrase, le Multi-Head Attention utilise plusieurs "têtes" qui regardent la phrase sous différents angles. C'est comme avoir plusieurs experts qui analysent le même texte : un grammairien, un spécialiste du sens, un expert en pronoms, etc. Chaque tête se spécialise et ensemble, elles donnent une compréhension complète !
🎮 Visualisez l'attention en action !
Maintenant que vous comprenez la théorie, expérimentez par vous-même ! Saisissez une phrase et observez comment les mots se connectent entre eux grâce au mécanisme d'attention.
Cliquez sur un mot pour voir ses connexions d'attention
Cette démonstration simule le mécanisme d'attention d'un Transformer de manière simplifiée. Dans un vrai modèle, les scores d'attention sont calculés à partir de représentations vectorielles apprises (Query, Key, Value).
Observations typiques :
- Les mots s'attendent fortement à eux-mêmes (diagonale de la matrice)
- Les pronoms (il, elle) créent des liens forts avec les noms qui les précèdent
- Les verbes se connectent aux sujets de la phrase
- Les mots adjacents ont généralement des scores d'attention modérés
Note : Cette simulation utilise des règles heuristiques simples. Un vrai Transformer apprend ces patterns automatiquement à partir de millions d'exemples.
Matrice d'attention (Self-Attention)
| Le | chat | mange | la | souris | |
|---|---|---|---|---|---|
| Le | 62% | 23% | 5% | 5% | 5% |
| chat | 19% | 53% | 19% | 4% | 4% |
| mange | 3% | 15% | 41% | 15% | 25% |
| la | 4% | 4% | 19% | 53% | 19% |
| souris | 4% | 4% | 28% | 17% | 47% |
💡 Comment lire cette matrice ?
- • Lignes : Le mot qui "observe" (Query)
- • Colonnes : Les mots observés (Keys)
- • Valeurs : Pourcentage d'attention accordé
- • Diagonale : Self-attention (un mot se regarde lui-même)
Note : Cette visualisation utilise des heuristiques simplifiées à des fins pédagogiques. Un vrai Transformer apprend ces poids d'attention pendant l'entraînement.
Pourquoi l'attention est révolutionnaire ?
Contrairement aux RNN qui traitent les mots séquentiellement, l'attention permet de traiter tous les mots simultanément, accélérant considérablement l'entraînement.
L'attention peut connecter des mots très éloignés dans la phrase sans perte d'information, résolvant le problème de la disparition du gradient des RNN.
Les poids d'attention peuvent être visualisés pour comprendre quelles relations le modèle a apprises, offrant une fenêtre sur son raisonnement.
Que représentent les Query, Key et Value dans le mécanisme d'attention ?
Quiz Vrai ou Faux
Vérifiez votre compréhension du mécanisme d'attention
Dans le mécanisme d'attention, Q (Query), K (Key) et V (Value) sont trois matrices différentes calculées à partir du même input.
Quiz Glisser-Déposer
Ordonnez les étapes du traitement dans un Transformer
Ordonnez le traitement d'un token à travers une couche Transformer
💡 Indice : Attention d'abord, puis Feed-Forward. N'oubliez pas les connexions résiduelles entre chaque bloc.
Glissez les éléments pour les ordonner correctement, ou utilisez les boutons ⬆️ ⬇️
Quiz de Correspondance
Associez chaque composant de l'attention à son rôle
Associez chaque composant de l'attention à son rôle
Cliquez sur un concept puis sur sa définition pour les associer
CONCEPTS
DÉFINITIONS
Votre retour est précieux pour améliorer cette page. Partagez votre expérience ci-dessous.
Comment évaluez-vous cette page ?
Pages connexes
Continuez votre apprentissage avec ces sujets liés